%%capture
!pip install pytorch-lightning
!pip install torchmetricsAttention based LSTM for Aspect level Sentiment Classification
Tutorials / Implementations
NLP
Attention-based LSTM for Aspect-level Sentiment Classification
The full notebook is available here.
Introduction
Aspect-level sentiment classification is a fine- grained task in sentiment analysis. Since it provides more complete and in-depth results, aspect-level sentiment analysis has received much attention these years. In this paper, we reveal that the sentiment polarity of a sentence is not only determined by the content but is also highly related to the concerned aspect. For instance, “The appetizers are ok, but the service is slow.”, for aspect taste, the polarity is positive while for service, the polarity is negative. Therefore, it is worthwhile to explore the connection between an aspect and the content of a sentence. To this end, we propose an Attention-based Long Short-Term Memory Network for aspect-level sentiment classification. The attention mechanism can concentrate on different parts of a sentence when different aspects are taken as input. We experiment on the SemEval 2014 dataset and results show that our model achieves state-of- the-art performance on aspect-level sentiment classification.
Install required packages
Import required packages
import os
import pickle
from collections import Counter, OrderedDict
from pathlib import Path
from typing import Any, Dict, List, Optional, Tuple, Union
from urllib.request import urlretrieve
import numpy as np
from tqdm import tqdm
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchmetrics
import torchtext
from pytorch_lightning import loggers as pl_loggers
from pytorch_lightning.callbacks import ModelCheckpoint
from torch.nn.utils.rnn import (pack_padded_sequence, pad_packed_sequence,
pad_sequence)
from torch.utils.data import DataLoader, Dataset, random_split
from torchtext.data import get_tokenizer
from torchtext.vocab import Vectors, Vocab
import xml.etree.ElementTree as ET
# For repoducibility
pl.utilities.seed.seed_everything(seed=2401, workers=True)/usr/local/lib/python3.7/dist-packages/pytorch_lightning/metrics/__init__.py:44: LightningDeprecationWarning: `pytorch_lightning.metrics.*` module has been renamed to `torchmetrics.*` and split off to its own package (https://github.com/PyTorchLightning/metrics) since v1.3 and will be removed in v1.5
"`pytorch_lightning.metrics.*` module has been renamed to `torchmetrics.*` and split off to its own package"
Global seed set to 24012401Define dataset, data module class, utils function
class TqdmUpTo(tqdm):
"""From https://github.com/tqdm/tqdm/blob/master/examples/tqdm_wget.py"""
def update_to(self, blocks=1, bsize=1, tsize=None):
"""
Parameters
----------
blocks: int, optional
Number of blocks transferred so far [default: 1].
bsize: int, optional
Size of each block (in tqdm units) [default: 1].
tsize: int, optional
Total size (in tqdm units). If [default: None] remains unchanged.
"""
if tsize is not None:
self.total = tsize
self.update(blocks * bsize - self.n)
class Tokenizer():
def __init__(self, tokenizer: Any):
self.counter = Counter(['<pad>', '<unk>'])
self.tokenizer = tokenizer
self.vocab = self.update_vocab()
def update_vocab(self):
sorted_by_freq_tuples = sorted(self.counter.items(), key=lambda x: x[1], reverse=True)
ordered_dict = OrderedDict(sorted_by_freq_tuples)
self.vocab = torchtext.vocab.vocab(ordered_dict, min_freq=1)
def fit_on_texts(self, texts: List[str]):
"""
Updates internal vocabulary based on a list of texts.
"""
# lower and tokenize texts to sequences
for text in texts:
self.counter.update(self.tokenizer(text))
self.update_vocab()
def texts_to_sequences(self, texts: List[str], reverse: bool=False, tensor: bool=True) -> List[int]:
word2idx = self.vocab.get_stoi()
sequences = []
for text in texts:
seq = [word2idx.get(word, word2idx['<unk>']) for word in self.tokenizer(text)]
if reverse:
seq = seq[::-1]
if tensor:
seq = torch.tensor(seq)
sequences.append(seq)
return sequences
def download_url(url, filename, directory='.'):
"""Download a file from url to filename, with a progress bar."""
if not os.path.exists(directory):
os.makedirs(directory)
path = os.path.join(directory, filename)
with TqdmUpTo(unit="B", unit_scale=True, unit_divisor=1024, miniters=1) as t:
urlretrieve(url, path, reporthook=t.update_to, data=None) # nosec
return path
def _preprocess_data(data, tokenizer, mapping_polarity, mapping_aspect):
sentences, text_aspects, text_sentiments = data
# Create sentence sequences and aspects sequences
sequences = tokenizer.texts_to_sequences(sentences)
sentiments = []
for val in text_sentiments:
sentiments.append(mapping_polarity[val])
sentiments = torch.tensor(sentiments)
aspects = []
for val in text_aspects:
aspects.append(mapping_aspect[val])
aspects = torch.tensor(aspects)
# pad sequences
seq_lens = torch.tensor([len(seq) for seq in sequences])
sequences = pad_sequence(sequences, batch_first=True)
assert len(sequences) == len(sentiments)
assert len(sequences) == len(aspects)
all_data = []
for i in range(len(sentiments)):
sample = {
'sequence': sequences[i],
'seq_len': seq_lens[i],
'aspect': aspects[i],
'sentiment': sentiments[i]
}
all_data.append(sample)
return all_data
def load_data_from(path: Union[str, Path]):
tree = ET.parse(path)
root = tree.getroot()
sentences = []
aspects = []
sentiments = []
for sent in root:
text = ''
for i, child in enumerate(sent):
if i == 0:
text = child.text
elif i == 2:
for aspect in child:
# Get polarities
polarity = aspect.attrib['polarity'].lower().strip()
if polarity == "conflict":
continue
sentiments.append(polarity)
# Get aspects
asp = aspect.attrib['category'].lower().strip()
if asp == 'anecdotes/miscellaneous':
aspects.append('miscellaneous')
else:
aspects.append(asp)
# Get sentences
sentences.append(text)
return sentences, aspects, sentiments
def build_vocab(tokenizer, data):
sentences = data[0]
tokenizer.fit_on_texts(sentences)
def load_pretrained_word_embeddings(options: Dict[str, Any]):
return torchtext.vocab.GloVe(options['name'], options['dim'])
def create_embedding_matrix(word_embeddings: Vectors, vocab: Vocab, path: Union[str, Path]):
if os.path.exists(path):
print(f'loading embedding matrix from {path}')
embedding_matrix = pickle.load(open(path, 'rb'))
else:
embedding_matrix = torch.zeros((len(vocab), word_embeddings.dim),
dtype=torch.float)
# words that are not availabel in the pretrained word embeddings will be zeros
for word, index in vocab.get_stoi().items():
embedding_matrix[index] = word_embeddings.get_vecs_by_tokens(word)
# save embedding matrix
pickle.dump(embedding_matrix, open(path, 'wb'))
return embedding_matrixclass SemEvalDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]TRAIN_DS_URL = 'https://raw.githubusercontent.com/zhangjf-nlp/ATAE-LSTM/master/data/restaurants-train.xml'
VALID_DS_URL = 'https://raw.githubusercontent.com/zhangjf-nlp/ATAE-LSTM/master/data/restaurants-trial.xml'
TEST_DS_URL = "https://raw.githubusercontent.com/AlexYangLi/ABSA_Keras/master/raw_data/semeval14_restaurant/Restaurants_Test_Gold.xml"
class SemEval2014(pl.LightningDataModule):
def __init__(self, tokenizer, opts):
super().__init__()
self.tokenizer = tokenizer
self.batch_size = opts['batch_size']
self.num_workers = opts['num_workers']
self.on_gpu = opts['on_gpu']
self.mapping = {"negative": 0, "neutral": 1, "positive": 2}
self.mapping_aspects = {'ambience': 0, 'food': 1, 'miscellaneous': 2,
'price': 3, 'service': 4}
self.inverse_mapping = {v: k for k, v in enumerate(self.mapping)}
def prepare_data(self, *args, **kwargs) -> None:
self.train_path = 'download/SemEval2014/train.xml'
self.valid_path = 'download/SemEval2014/valid.xml'
self.test_path = 'download/SemEval2014/test.xml'
if not os.path.exists(train_path):
print("Downloading train dataset")
self.train_path = download_url(TRAIN_DS_URL, 'train.xml', 'download/SemEval2014')
if not os.path.exists(valid_path):
print("Downloading valid dataset")
self.valid_path = download_url(VALID_DS_URL, 'valid.xml', 'download/SemEval2014')
if not os.path.exists(test_path):
print("Downloading test dataset")
self.test_path = download_url(TEST_DS_URL, 'test.xml', 'download/SemEval2014')
def setup(self, stage: str = None) -> None:
if stage == 'fit' or stage is None:
# Load data from files
train_data = load_data_from(self.train_path)
valid_data = load_data_from(self.valid_path)
self.train_data = _preprocess_data(train_data, self.tokenizer, self.mapping, self.mapping_aspects)
self.val_data = _preprocess_data(valid_data, self.tokenizer, self.mapping, self.mapping_aspects)
elif stage == 'test' or stage is None:
test_data = load_data_from(self.test_path)
self.test_data = _preprocess_data(test_data, self.tokenizer, self.mapping, self.mapping_aspects)
def train_dataloader(self):
# Create Dataset object
train_ds = SemEvalDataset(self.train_data)
# Create Dataloader
return DataLoader(
train_ds,
shuffle=True,
batch_size=self.batch_size,
num_workers=self.num_workers,
pin_memory=self.on_gpu,
)
def val_dataloader(self):
val_ds = SemEvalDataset(self.val_data)
return DataLoader(
val_ds,
shuffle=False,
batch_size=self.batch_size,
num_workers=self.num_workers,
pin_memory=self.on_gpu,
)
def test_dataloader(self):
test_ds = SemEvalDataset(self.test_data)
return DataLoader(
test_ds,
shuffle=False,
batch_size=self.batch_size,
num_workers=self.num_workers,
pin_memory=self.on_gpu,
)
def __repr__(self):
basic = f"SemEval2014 Dataset\nNum classes: {len(self.mapping)}\nMapping: {self.mapping}\n"
if self.train_data is None and self.val_data is None and self.test_data is None:
return basic
batch = next(iter(self.train_dataloader()))
sequences, seq_lens, aspects, sentiments = batch['sequence'], batch['seq_len'], batch['aspect'], batch['sentiment']
data = (
f"Train/val/test sizes: {len(self.train_data)}, {len(self.val_data)}, {len(self.test_data)}\n"
f"Batch sequences stats: {(sequences.shape, sequences.dtype)}\n"
f"Batch seq_lens stats: {(seq_lens.shape, seq_lens.dtype)}\n"
f"Batch aspects stats: {(aspects.shape, aspects.dtype)}\n"
f"Batch sentiments stats: {(sentiments.shape, sentiments.dtype)}\n"
)
return basic + dataImplementation
AT-LSTM
LSTM with Aspect Embedding (AE-LSTM)
Aspect information is important when doing classificaiton on the sentence. We may get different polarities with different aspects. The author proposed to learn an embedding vector for each aspect.
Attention-based LSTM (AT-LSTM)
The standard LSTM cannot detect which is the important part for aspect-level sentiment classification. The author proposed to design an attention mechanism capturing the key part of sentence in response to a given aspect.
from IPython.display import Image
Image(filename='/Users/minhdang/Desktop/AT-LSTM.png')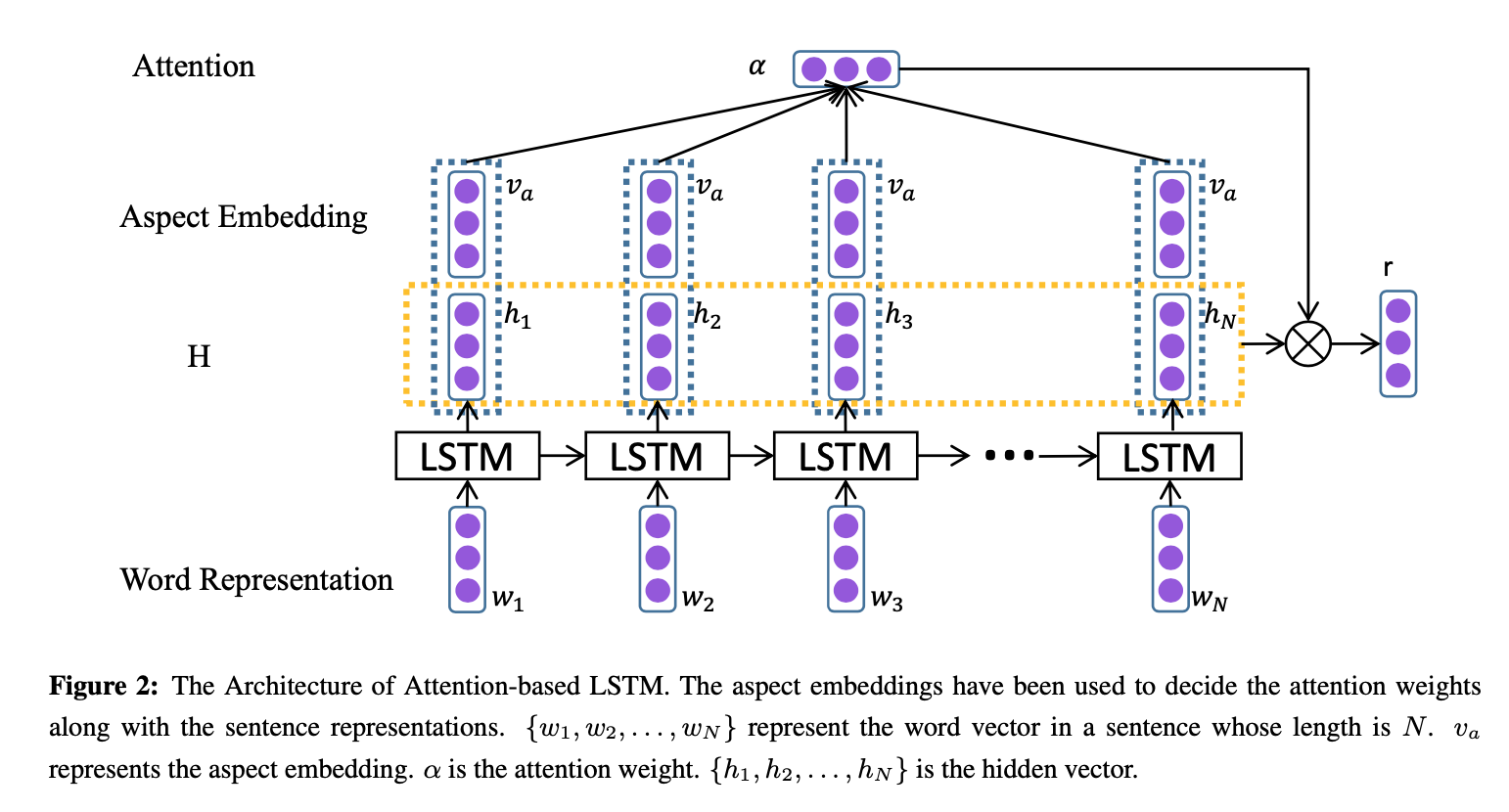
class AT_LSTM(pl.LightningModule):
def __init__(self, embeddings, hidden_size, aspect_hidden_size, num_layers=1, num_classes=3, batch_first=True, lr=1e-3, dropout=0, l2reg=0.01):
super().__init__()
embedding_dim = embeddings.shape[1]
self.embedding = nn.Embedding.from_pretrained(embeddings) # load pre-trained word embeddings
self.aspect_embedding = nn.Embedding(5, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_size, num_layers, batch_first=batch_first, dropout=dropout)
self.linear_h = nn.Linear(hidden_size, hidden_size, bias=False)
self.linear_v = nn.Linear(aspect_hidden_size, aspect_hidden_size, bias=False)
self.linear_p = nn.Linear(hidden_size, hidden_size, bias=False)
self.linear_x = nn.Linear(hidden_size, hidden_size, bias=False)
self.linear = nn.Linear(hidden_size + aspect_hidden_size, 1)
self.linear_s = nn.Linear(hidden_size, num_classes)
self.batch_first = batch_first
self.lr = lr
self.l2reg = l2reg
# Define metrics
self.train_acc = torchmetrics.Accuracy()
self.val_acc = torchmetrics.Accuracy()
self.val_f1 = torchmetrics.F1(num_classes=3, average='macro')
self.test_acc = torchmetrics.Accuracy()
self.test_f1 = torchmetrics.F1(num_classes=3, average='macro')
def configure_optimizers(self):
optim = torch.optim.Adam(self.parameters(), lr=self.lr, weight_decay=self.l2reg)
return optim
def forward(self, input):
sequences, seq_lens, aspect_seqs = input['sequence'], input['seq_len'], input['aspect']
# Covert sequence to embeddings
embeds = self.embedding(sequences)
# Get the max sequence length
max_seq_len = torch.max(seq_lens)
# Convert aspect to embeddings
aspect_embeds = self.aspect_embedding(aspect_seqs)
packed_embeds = pack_padded_sequence(embeds, seq_lens.cpu(), batch_first=self.batch_first, enforce_sorted=False)
H, (h, c) = self.lstm(packed_embeds)
padded_H, lens = pad_packed_sequence(H, batch_first=True)
Wh_H = self.linear_h(padded_H)
Wv_va = self.linear_v(aspect_embeds)
Wv_va = Wv_va.unsqueeze(1).repeat(1, max_seq_len, 1)
M = torch.tanh(torch.cat([Wh_H, Wv_va], dim=-1))
# Calculate attention score
score = self.linear(M).squeeze()
att_mask = torch.arange(max_seq_len, device=self.device)[None,:] < seq_lens[:, None]
# Create mask to zero out attention scores for padding tokens
score[~att_mask] = float('-inf')
alpha = F.softmax(score, dim=-1).unsqueeze(2)
r = torch.matmul(padded_H.transpose(-2,-1), alpha).squeeze()
final_h = torch.tanh(self.linear_p(r) + self.linear_x(h[-1]))
out = self.linear_s(final_h)
return out
def training_step(self, batch, batch_idx):
sentiments = batch['sentiment']
logits = self.forward(batch)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.train_acc(scores, sentiments)
self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('train_acc', self.train_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.val_acc(scores, sentiments)
self.val_f1(scores, sentiments)
self.log('val_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('val_acc', self.val_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
self.log('val_f1', self.val_f1, on_step=False, on_epoch=True, prog_bar=True, logger=True)
def test_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
scores = F.softmax(logits, dim=-1)
self.test_acc(scores, sentiments)
self.test_f1(scores, sentiments)
self.log('test_acc', self.test_acc, on_step=False, on_epoch=True, logger=True)
self.log('test_f1', self.test_f1, on_step=False, on_epoch=True, logger=True)ATAE-LSTM
To take advanatage of aspect information, we append the input aspect embedding into each word input vector. By doing that, the inter-dependence between words and the input aspect can be modeled.
from IPython.display import Image
Image(filename='/Users/minhdang/Desktop/ATAE-LSTM.png')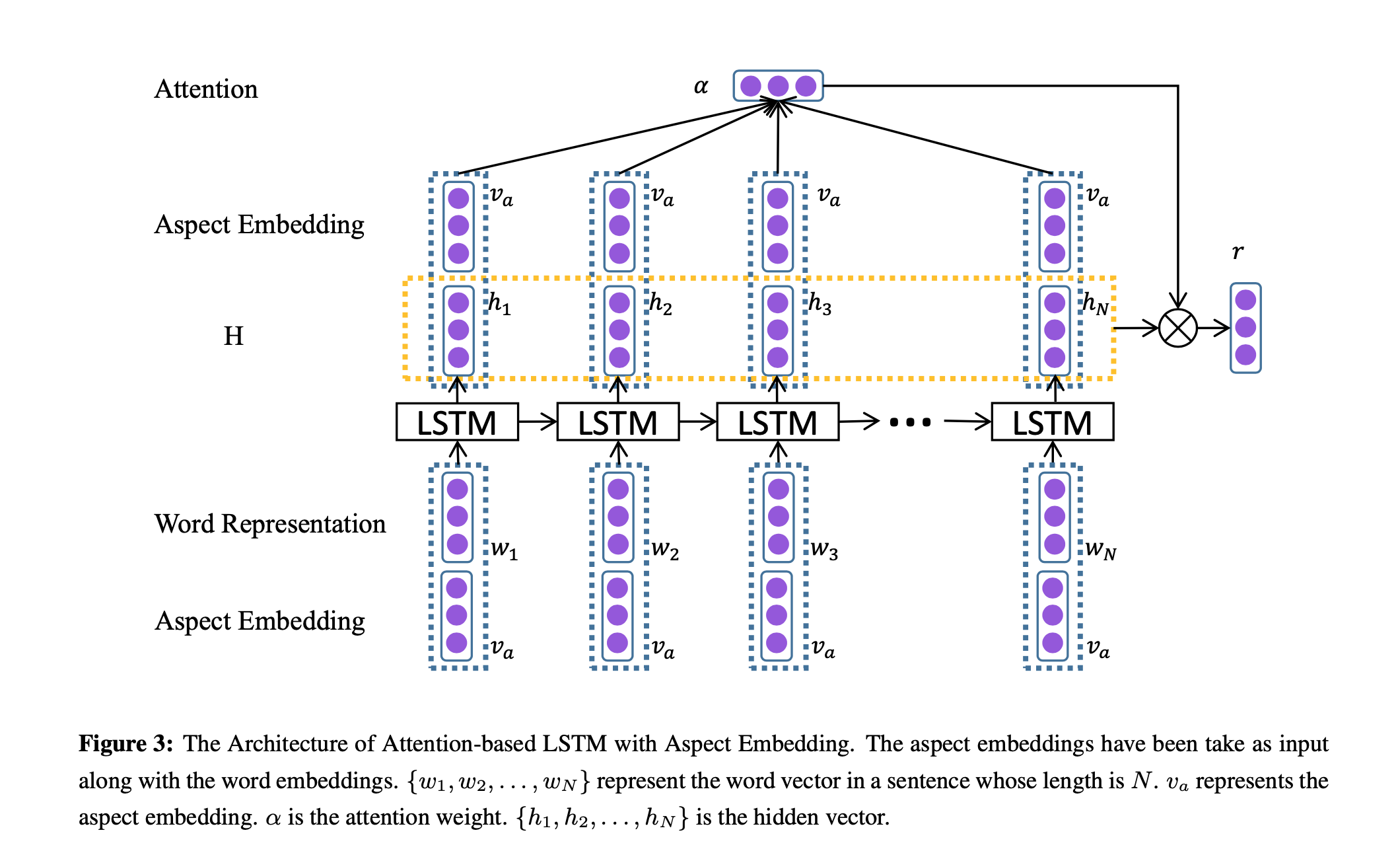
class ATAE_LSTM(pl.LightningModule):
def __init__(self, embeddings, hidden_size, aspect_hidden_size, num_layers=1, num_classes=3, batch_first=True, lr=1e-3, dropout=0, l2reg=0.01):
super().__init__()
embedding_dim = embeddings.shape[1]
self.embedding = nn.Embedding.from_pretrained(embeddings) # load pre-trained word embeddings
self.aspect_embedding = nn.Embedding(5, embedding_dim)
self.lstm = nn.LSTM(2*embedding_dim, hidden_size, num_layers, batch_first=batch_first, dropout=dropout)
self.linear_h = nn.Linear(hidden_size, hidden_size, bias=False)
self.linear_v = nn.Linear(aspect_hidden_size, aspect_hidden_size, bias=False)
self.linear_p = nn.Linear(hidden_size, hidden_size, bias=False)
self.linear_x = nn.Linear(hidden_size, hidden_size, bias=False)
self.linear = nn.Linear(hidden_size + aspect_hidden_size, 1)
self.linear_s = nn.Linear(hidden_size, num_classes)
self.batch_first = batch_first
self.lr = lr
self.l2reg = l2reg
# Define metrics
self.train_acc = torchmetrics.Accuracy()
self.val_acc = torchmetrics.Accuracy()
self.val_f1 = torchmetrics.F1(num_classes=3, average='macro')
self.test_acc = torchmetrics.Accuracy()
self.test_f1 = torchmetrics.F1(num_classes=3, average='macro')
def configure_optimizers(self):
optim = torch.optim.Adam(self.parameters(), lr=self.lr, weight_decay=self.l2reg)
return optim
def forward(self, input):
sequences, seq_lens, aspect_seqs = input['sequence'], input['seq_len'], input['aspect']
# Covert sequence to embeddings
embeds = self.embedding(sequences)
# Get the max sequence length
max_seq_len = torch.max(seq_lens)
# Convert aspect to embeddings
aspect_embeds = self.aspect_embedding(aspect_seqs)
# Repeat the aspect vector across the dimension 1
aspect_embeds_repeat = aspect_embeds.unsqueeze(1).repeat(1,embeds.shape[1],1)
# Append the aspect vector to the input word vector
embeds = torch.cat([embeds, aspect_embeds_repeat], dim=-1)
packed_embeds = pack_padded_sequence(embeds, seq_lens.cpu(), batch_first=self.batch_first, enforce_sorted=False)
H, (h, c) = self.lstm(packed_embeds)
padded_H, lens = pad_packed_sequence(H, batch_first=True)
Wh_H = self.linear_h(padded_H)
Wv_va = self.linear_v(aspect_embeds)
Wv_va = Wv_va.unsqueeze(1).repeat(1, max_seq_len, 1)
M = torch.tanh(torch.cat([Wh_H, Wv_va], dim=-1))
# Calculate attention score
score = self.linear(M).squeeze()
# Create mask to zero out attention scores for padding tokens
att_mask = torch.arange(max_seq_len, device=self.device)[None,:] < seq_lens[:, None]
score[~att_mask] = float('-inf')
alpha = F.softmax(score, dim=-1).unsqueeze(2)
r = torch.matmul(padded_H.transpose(-2,-1), alpha).squeeze()
final_h = torch.tanh(self.linear_p(r) + self.linear_x(h[-1]))
out = self.linear_s(final_h)
return out
def training_step(self, batch, batch_idx):
sentiments = batch['sentiment']
logits = self.forward(batch)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.train_acc(scores, sentiments)
self.log('train_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('train_acc', self.train_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
return loss
def validation_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
loss = F.cross_entropy(logits, sentiments)
scores = F.softmax(logits, dim=-1)
self.val_acc(scores, sentiments)
self.val_f1(scores, sentiments)
self.log('val_loss', loss, on_step=True, on_epoch=True, prog_bar=True)
self.log('val_acc', self.val_acc, on_step=False, on_epoch=True, prog_bar=True, logger=True)
self.log('val_f1', self.val_f1, on_step=False, on_epoch=True, prog_bar=True, logger=True)
def test_step(self, batch, batch_idx): # pylint: disable=unused-argument
sentiments = batch['sentiment']
logits = self.forward(batch)
scores = F.softmax(logits, dim=-1)
self.test_acc(scores, sentiments)
self.test_f1(scores, sentiments)
self.log('test_acc', self.test_acc, on_step=False, on_epoch=True, logger=True)
self.log('test_f1', self.test_f1, on_step=False, on_epoch=True, logger=True)
Training
word_embeddings = load_pretrained_word_embeddings({"name": "840B", "dim": 300})train_path = download_url(TRAIN_DS_URL, 'train.xml', 'download/SemEval2014')
valid_path = download_url(VALID_DS_URL, 'valid.xml', 'download/SemEval2014')
test_path = download_url(TEST_DS_URL, 'test.xml', 'download/SemEval2014')
train_data = load_data_from(train_path)
valid_data = load_data_from(valid_path)
test_data = load_data_from(test_path)
all_sentences = train_data[0] + valid_data[0] + test_data[0]
tokenizer = Tokenizer(get_tokenizer("basic_english"))
build_vocab(tokenizer, [all_sentences])
options = {
"on_gpu": True,
"batch_size": 64,
"num_workers": 2
}
datamodule = SemEval2014(tokenizer, options)
embedding_matrix = create_embedding_matrix(word_embeddings, tokenizer.vocab, "embedding_matrix.dat")1.18MB [00:00, 9.47MB/s]
40.0kB [00:00, 1.78MB/s]
352kB [00:00, 12.3MB/s]loading embedding matrix from embedding_matrix.datAT-LSTM
checkpoint_callback = ModelCheckpoint(
monitor='val_acc', # save the model with the best validation accuracy
dirpath='checkpoints',
mode='max',
)
tb_logger = pl_loggers.TensorBoardLogger('logs/') # create logger for tensorboard
# Set hyper-parameters
lr = 1e-3
hidden_size = 300
aspect_embedding_dim = 300
num_epochs = 30
l2reg = 0.0
trainer = pl.Trainer(gpus=1, max_epochs=num_epochs, logger=tb_logger, callbacks=[checkpoint_callback], deterministic=True)
# trainer = pl.Trainer(fast_dev_run=True) #Debug
# trainer = pl.Trainer(overfit_batches=0.025, max_epochs=num_epochs) #Debug
model = AT_LSTM(embedding_matrix, hidden_size, aspect_embedding_dim, lr=lr, l2reg=l2reg)
trainer.fit(model, datamodule)GPU available: True, used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
------------------------------------------------
0 | embedding | Embedding | 1.3 M
1 | aspect_embedding | Embedding | 1.5 K
2 | lstm | LSTM | 722 K
3 | linear_h | Linear | 90.0 K
4 | linear_v | Linear | 90.0 K
5 | linear_p | Linear | 90.0 K
6 | linear_x | Linear | 90.0 K
7 | linear | Linear | 601
8 | linear_s | Linear | 903
9 | train_acc | Accuracy | 0
10 | val_acc | Accuracy | 0
11 | val_f1 | F1 | 0
12 | test_acc | Accuracy | 0
13 | test_f1 | F1 | 0
------------------------------------------------
1.1 M Trainable params
1.3 M Non-trainable params
2.4 M Total params
9.708 Total estimated model params size (MB)Global seed set to 2401trainer.test(ckpt_path=checkpoint_callback.best_model_path)LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
--------------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'test_acc': 0.8150510191917419, 'test_f1': 0.6747192740440369}
--------------------------------------------------------------------------------[{'test_acc': 0.8150510191917419, 'test_f1': 0.6747192740440369}]ATAE-LSTM
checkpoint_callback = ModelCheckpoint(
monitor='val_acc', # save the model with the best validation accuracy
dirpath='checkpoints',
mode='max',
)
tb_logger = pl_loggers.TensorBoardLogger('logs/') # create logger for tensorboard
# Set hyper-parameters
lr = 1e-3
hidden_size = 300
aspect_embedding_dim = 300
num_epochs = 30
l2reg = 0.0
trainer = pl.Trainer(gpus=1, max_epochs=num_epochs, logger=tb_logger, callbacks=[checkpoint_callback], deterministic=True)
# trainer = pl.Trainer(fast_dev_run=True) #Debug
# trainer = pl.Trainer(overfit_batches=0.025, max_epochs=num_epochs) #Debug
model = ATAE_LSTM(embedding_matrix, hidden_size, aspect_embedding_dim, lr=lr, l2reg=l2reg)
trainer.fit(model, datamodule)GPU available: True, used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
------------------------------------------------
0 | embedding | Embedding | 1.3 M
1 | aspect_embedding | Embedding | 1.5 K
2 | lstm | LSTM | 1.1 M
3 | linear_h | Linear | 90.0 K
4 | linear_v | Linear | 90.0 K
5 | linear_p | Linear | 90.0 K
6 | linear_x | Linear | 90.0 K
7 | linear | Linear | 601
8 | linear_s | Linear | 903
9 | train_acc | Accuracy | 0
10 | val_acc | Accuracy | 0
11 | val_f1 | F1 | 0
12 | test_acc | Accuracy | 0
13 | test_f1 | F1 | 0
------------------------------------------------
1.4 M Trainable params
1.3 M Non-trainable params
2.8 M Total params
11.148 Total estimated model params size (MB)Global seed set to 2401trainer.test(ckpt_path=checkpoint_callback.best_model_path)LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
--------------------------------------------------------------------------------
DATALOADER:0 TEST RESULTS
{'test_acc': 0.8227040767669678, 'test_f1': 0.6682634353637695}
--------------------------------------------------------------------------------[{'test_acc': 0.8227040767669678, 'test_f1': 0.6682634353637695}]Discussion
Since I could not find out the exact dataset used in the paper, it is impossible to compare with the paper’s result. Instead, I will compare my implementation with other implementations from Github.
Our result
| Model | Accuracy | F1 macro |
|---|---|---|
| AT-LSTM | 0.81 | 0.674 |
| ATAE-LSTM | 0.82 | 0.668 |
There is a unbalance between positive, negative and positive classes in both train, valid and test set. That’s the reason why we have the F1 macro lower than the accuracy.